Stackoverflow top QA¶
1. Stack Overflow 经典问题:排序数组为什么条件处理更快?¶
原问题标题:
Why is conditional processing of a sorted array faster than of an unsorted array?
问题核心代码可以简化为:
for (unsigned i = 0; i < 100000; ++i) {
for (unsigned c = 0; c < arraySize; ++c) {
if (data[c] >= 128)
sum += data[c];
}
}
题主发现,同样一段代码:
数组元素是 0 ~ 255 的随机数。排序本身不计入测试时间。
问题的反直觉之处在于:
求和操作彼此独立,数学结果不依赖数组顺序,为什么排序后执行速度会快这么多?
Top 3 回答总结¶
| 排名 | 回答者 | 核心观点 |
|---|---|---|
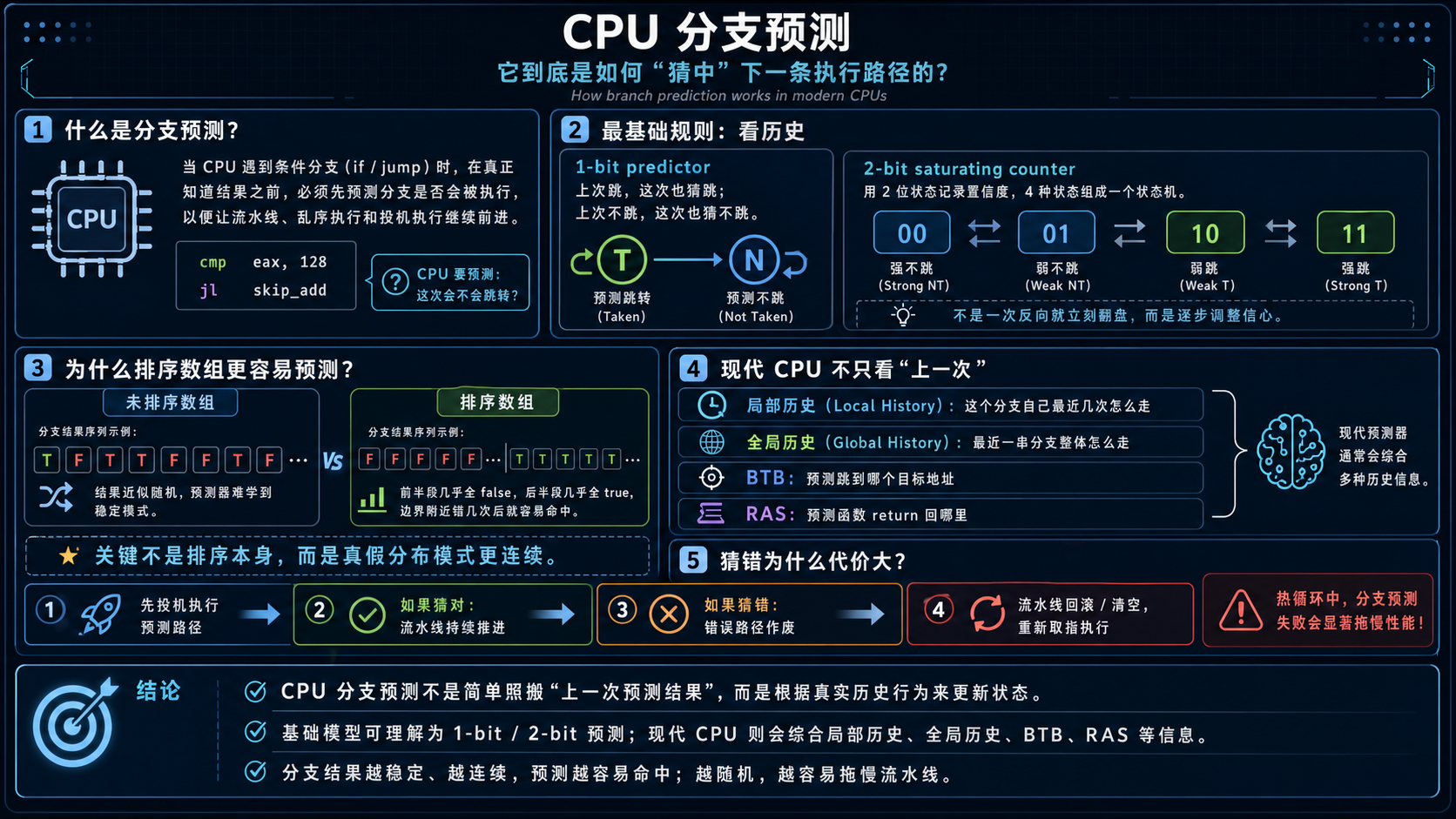
| 1 | Mysticial | 根因是 branch prediction fail,也就是分支预测失败。未排序数组中,data[c] >= 128 的真假结果近似随机,CPU 经常预测错误;排序后,判断结果变成连续的 false...false true...true,预测器很容易命中。 |
| 2 | Daniel Fischer | 本质就是 branch prediction。排序数组让条件分支方向高度规律,因此 CPU 可以稳定预测;未排序数组的分支方向近似随机,因此需要付出大量预测失败的代价。 |
| 3 | WiSaGaN | 可以使用 branchless / conditional move 写法,例如 sum += data[c] >= 128 ? data[c] : 0;,避免显式条件跳转。这样随机数组和排序数组的性能差距会明显缩小。 |
原理精髓¶
这道题的精髓不是“排序让加法更快”,也不是“排序让算法复杂度变低”。
真正的关键是:
这个条件判断在排序前后产生了完全不同的分支模式。
未排序数组:分支结果近似随机¶
数组元素是 0 ~ 255 的随机数,判断条件是:
所以大约一半元素满足条件,一半不满足条件。
未排序时,CPU 看到的分支结果类似:
其中:
这个序列接近随机。 CPU 分支预测器很难从中学习到稳定模式,因此预测失败率很高。
排序数组:分支结果变成连续区间¶
排序后,数组大致变成:
对应的判断结果变成:
也就是说:
这种模式对 CPU 非常友好。
分支预测器只需要在 127 → 128 的边界附近预测错几次,之后基本都能稳定预测正确。
分支预测失败为什么代价很高?¶
现代 CPU 使用流水线、乱序执行和投机执行。
遇到条件分支时,CPU 不会傻等判断结果出来,而是会先猜:
如果猜对:
如果猜错:
这就是分支预测失败的成本。
原问题中的判断次数非常大:
超过 32 亿次条件判断中,如果大量分支预测失败,累计性能损耗会非常明显。
这不是典型的 cache 问题¶
排序前后,数组访问方式都是顺序扫描:
内存访问模式基本一致。
真正变化的是:
所以本题主要不是缓存命中率问题,而是 控制流可预测性问题。
最关键的一句话¶
排序数组更快,不是因为排序改变了求和逻辑,也不是因为算法复杂度降低,而是因为排序让 if (data[c] >= 128) 的真假结果从随机序列变成连续序列,CPU 分支预测器几乎不再猜错,从而避免大量流水线回滚。
工程启示¶
热循环中的性能问题,不能只看算法复杂度,还要看 CPU 执行路径。
这道题可以总结为:
更进一步说,完整排序并不是必要条件。
如果只是为了让分支可预测,那么只需要把数据分成两组:
这就是 partition。
所以本题真正的技术内核是:
排序不是目的,让分支结果可预测才是目的。

2.Stack Overflow 经典问题:如何撤销最近一次本地 Git 提交?¶
原问题标题:
How do I undo the most recent local commits in Git?
题主场景:
我不小心把错误的文件提交到了 Git,但还没有 push 到服务器。如何从本地仓库撤销这些 commit?(Stack Overflow)
问题关键点是:
这类问题本质上不是“删除文件”,而是:
第一名答案总结¶
第一名答案的核心方案是:
git commit -m "Something terribly misguided" # 误提交
git reset HEAD~ # 撤销最近一次 commit
# 如果只是想撤销 commit,到这里就可以停止
# 如需修改后重新提交:
# edit files as necessary
git add .
git commit -c ORIG_HEAD
这个答案的重点是:使用 git reset HEAD~ 撤销最近一次本地提交,但保留工作区文件内容。也就是说,commit 被撤回了,但你刚才提交进去的代码还在,只是回到了未暂存或待重新暂存的状态。(Stack Overflow)
命令逐行解析¶
1. 误提交¶
含义:
假设提交历史是:
其中 C 就是刚刚误提交的 commit。
2. 撤销最近一次 commit¶
HEAD~ 等价于 HEAD~1,表示当前提交的上一个提交。第一名答案也明确提到,HEAD~ 和 HEAD~1 是同义用法。(Stack Overflow)
执行后,提交历史变成:
但注意:文件内容还在工作区里。
也就是说,Git 做的不是“删除你的代码”,而是:
这正是这个答案的核心。
3. 修改文件¶
现在你可以重新调整刚才误提交的文件,例如:
4. 重新暂存¶
把这次真正想提交的内容重新放入暂存区。
5. 复用原 commit message 重新提交¶
第一名答案解释:reset 会把原来的 HEAD 复制到 .git/ORIG_HEAD,然后 git commit -c ORIG_HEAD 会用旧提交信息作为初始提交信息,并打开编辑器允许你修改;如果不需要编辑提交信息,可以用 -C ORIG_HEAD。(Stack Overflow)
Git 官方文档也说明,reset 会把 old head 复制到 .git/ORIG_HEAD,可以用它基于旧日志信息重新提交。(Git)
原理精髓:reset 不是“删除”,而是移动 HEAD¶
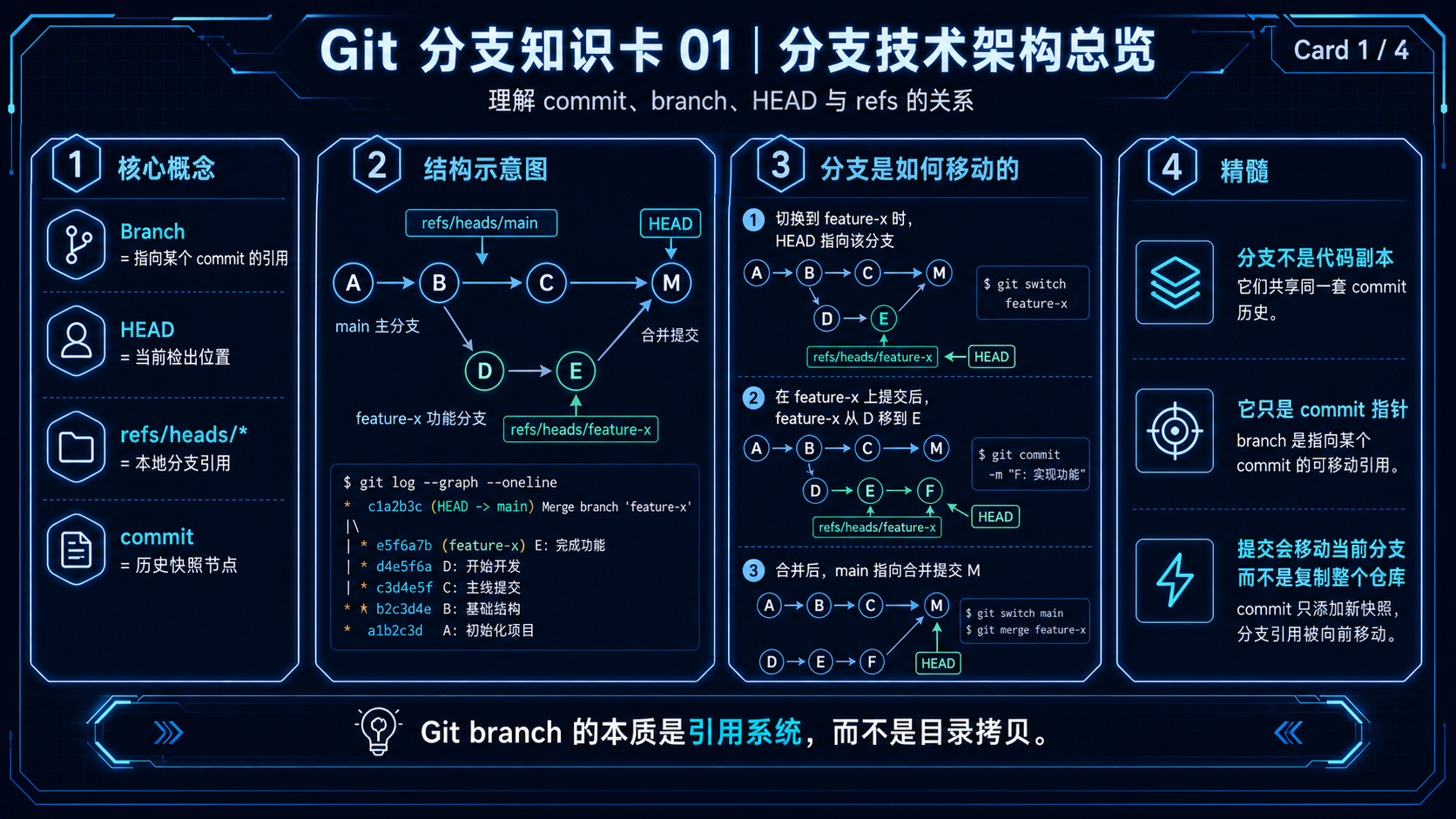
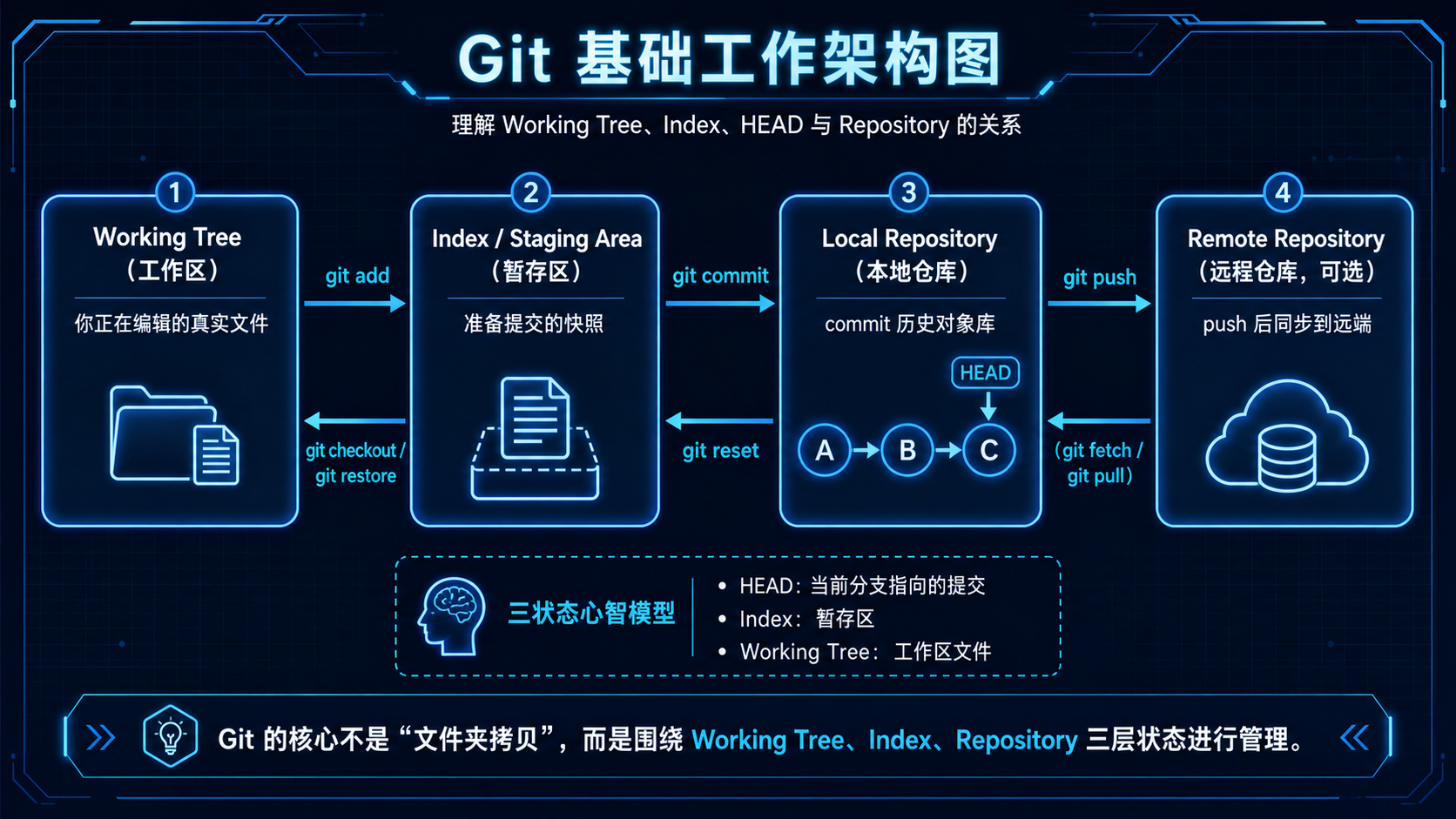
理解这个问题,要抓住 Git 的三层结构:
git reset 的本质是:
Git 官方文档中的 reset 行为表也能看出:--soft、--mixed、--hard 对 working tree、index、HEAD 的影响不同;其中 --mixed 会移动 HEAD 并重置 index,但保留 working tree。(Git)
git reset 的三种常用模式¶
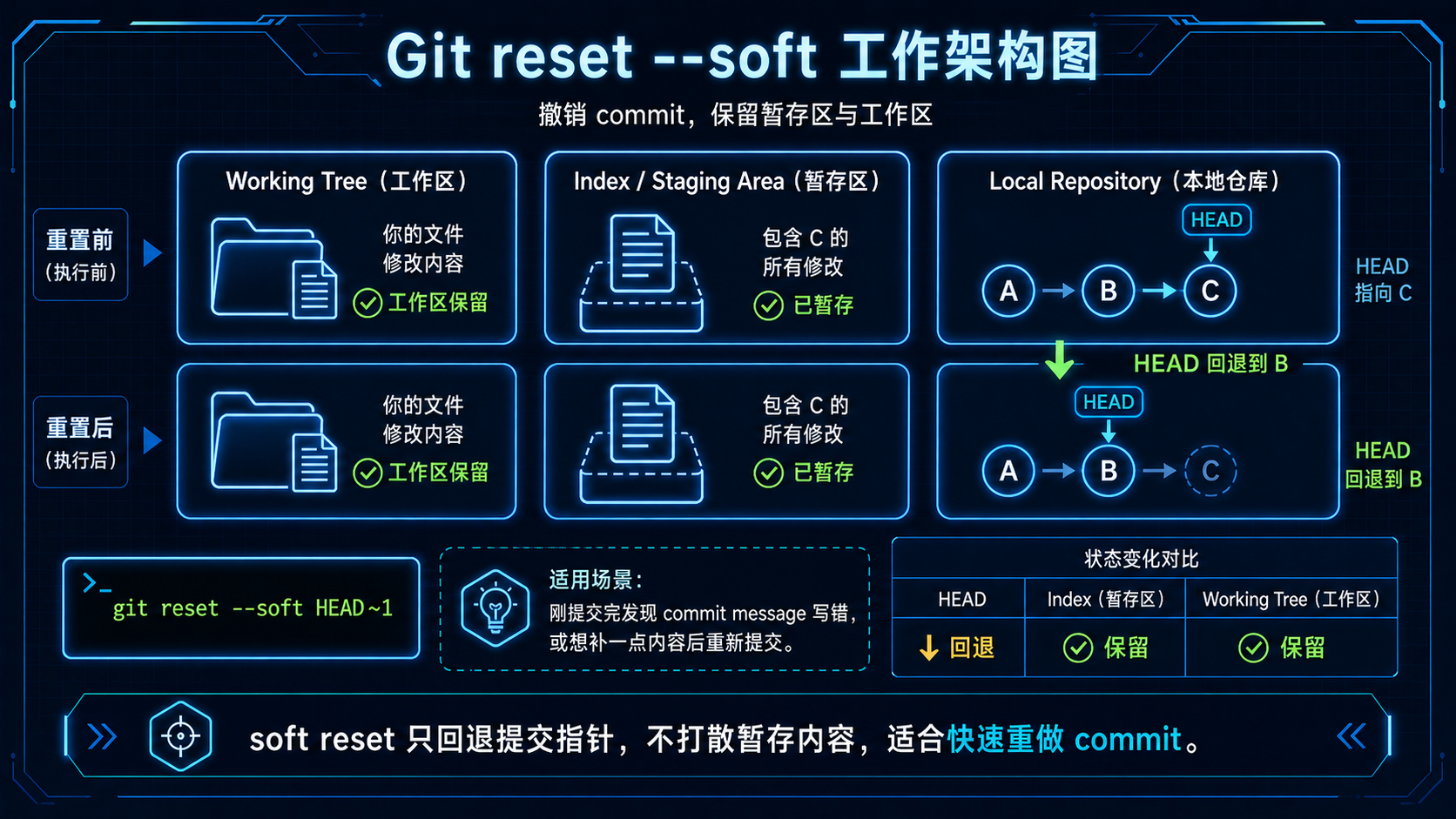
1. git reset --soft HEAD~1¶
效果:
适合场景:
状态变化:
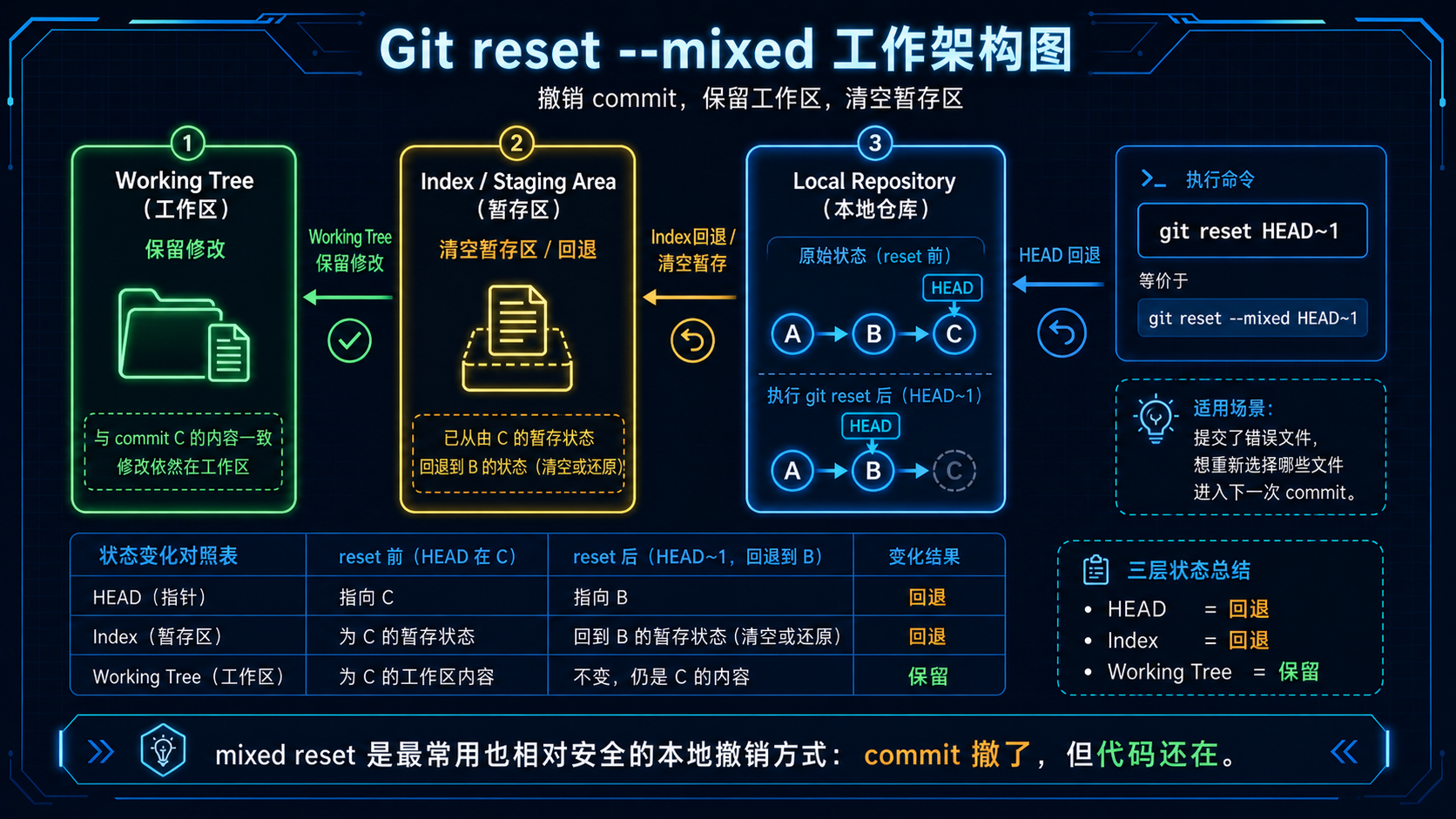
2. git reset HEAD~1¶
这也是第一名答案使用的方式。
它等价于:
效果:
适合场景:
状态变化:
这是最常用、也相对安全的撤销本地 commit 方式。
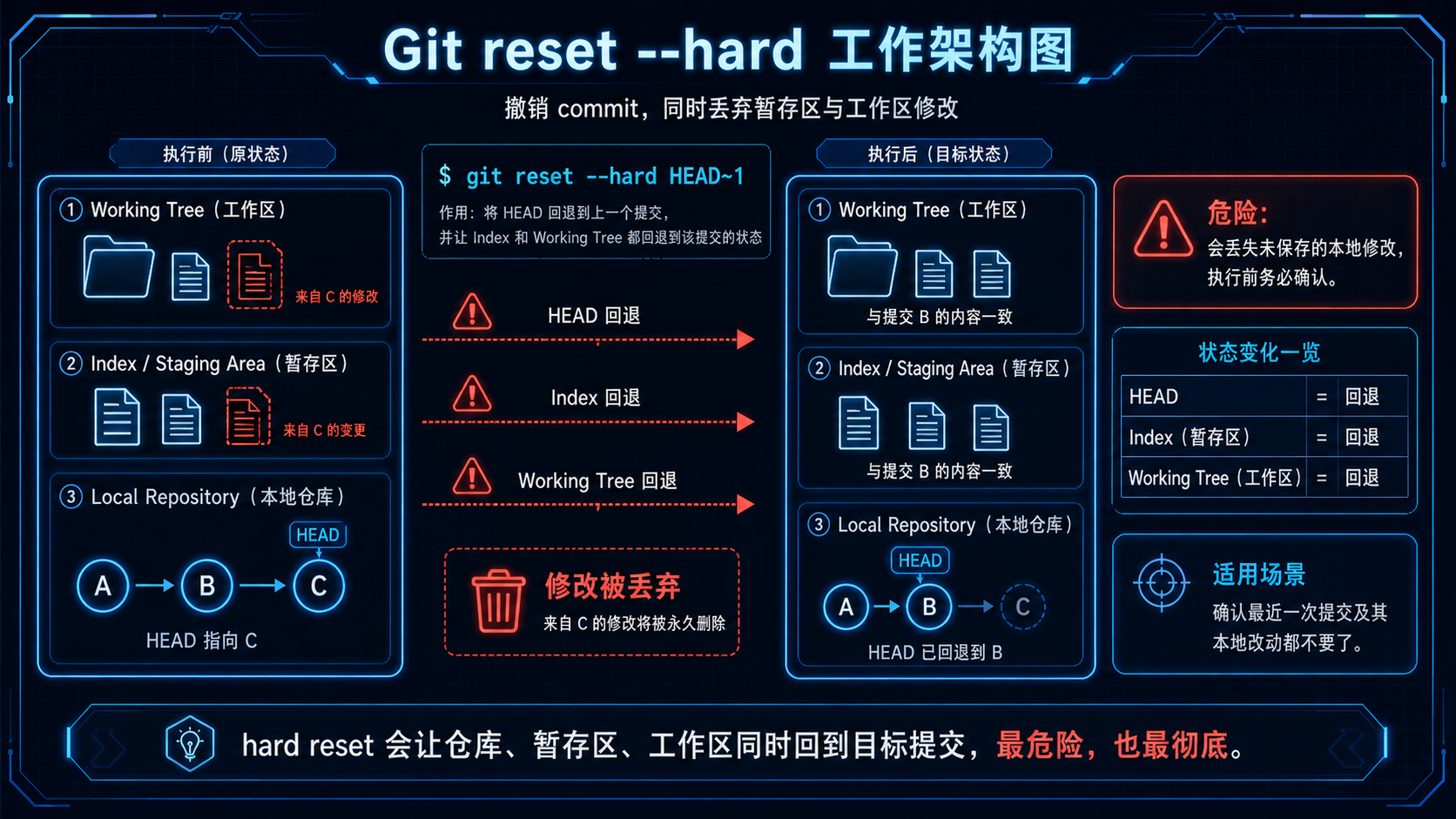
3. git reset --hard HEAD~1¶
效果:
状态变化:
这个命令危险得多。官方 reset 文档也显示 --hard 会让 working tree、index、HEAD 都回到目标状态。(Git)
除非你明确知道刚才的改动完全不要了,否则不要直接用它。
一张表理解 reset¶
| 命令 | HEAD | index 暂存区 | working tree 工作区 | 是否保留代码 |
|---|---|---|---|---|
git reset --soft HEAD~1 |
回退 | 保留 | 保留 | 保留,且仍在暂存区 |
git reset HEAD~1 |
回退 | 回退 | 保留 | 保留,但变成未暂存 |
git reset --hard HEAD~1 |
回退 | 回退 | 回退 | 不保留,危险 |
如果 commit 已经 push 了怎么办?¶
第一名答案讨论的是 local commits,也就是还没有 push 的提交。题主也明确说还没有 push 到服务器。(Stack Overflow)
如果 commit 已经 push 到远程仓库,就不能简单套用“本地撤销”的思路。
这时有两种路线:
如果是多人协作分支,通常更推荐 git revert,因为它不会改写已有历史,而是新建一个反向提交。Git 官方文档对 git revert 的定义也是:对已有 commit 引入的补丁做反向操作,并记录新的 commit。(Git)
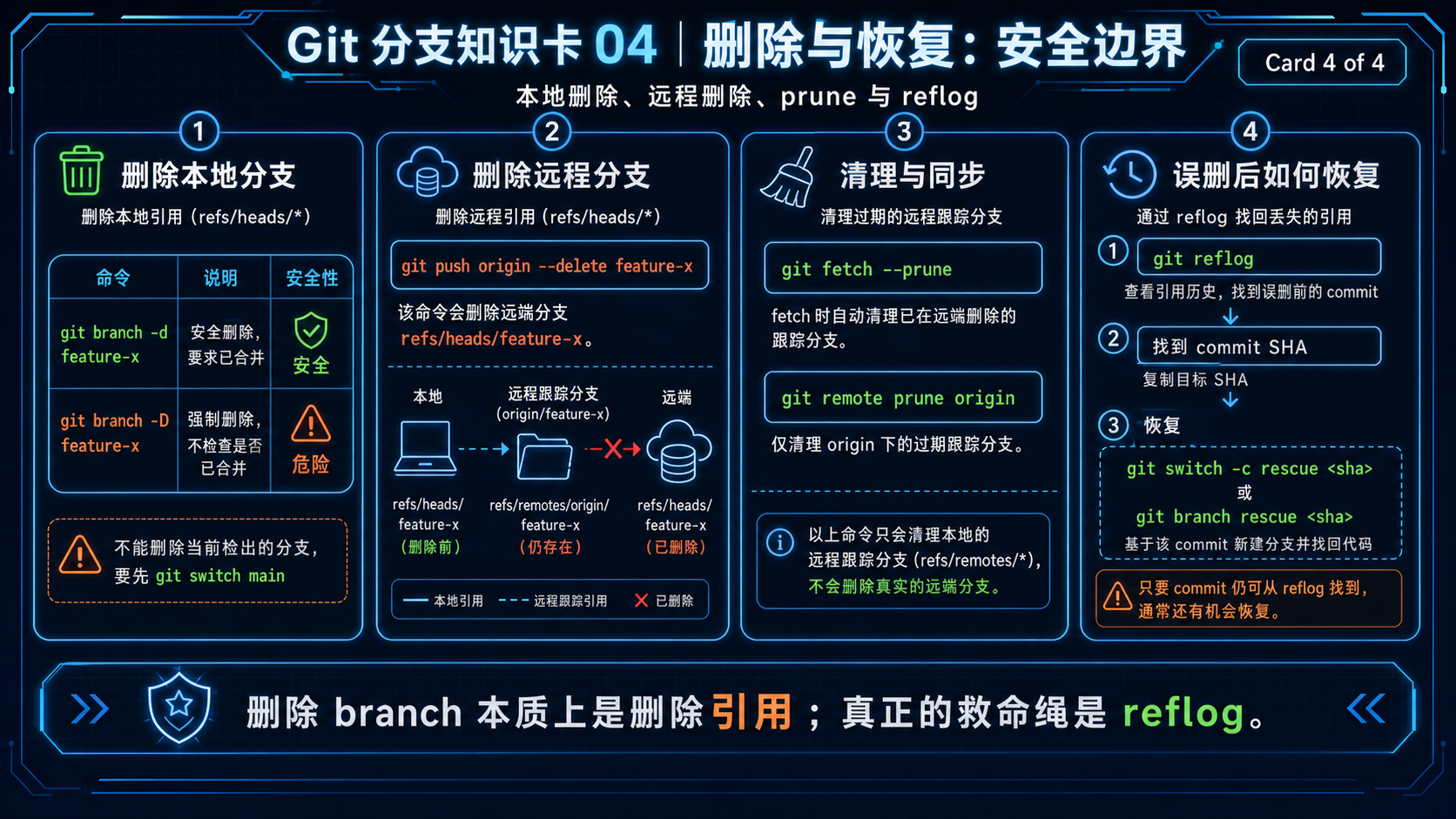
如果 reset 错了,还能恢复吗?¶
可以优先看:
reflog 记录本地仓库中分支和引用 tip 的变化历史,例如 HEAD@{2} 表示 HEAD 两次移动之前的位置。(Git)
典型恢复方式:
或者:
第一名答案后续也建议用 git reflog 找回要恢复的 commit SHA。(Stack Overflow)
最关键的一句话¶
撤销最近一次本地 Git commit,第一名答案推荐 git reset HEAD~:它不是删除你的代码,而是把 HEAD 从错误提交退回到上一个提交,同时保留工作区修改,让你可以重新选择文件、修改内容并再次提交。
工程启示¶
这道题的精髓是:
真正要记住的是:
想撤销 commit,但保留代码:git reset HEAD~1
想撤销 commit,并保持已暂存:git reset --soft HEAD~1
想彻底丢弃最近一次 commit 的代码:git reset --hard HEAD~1
已经 push 到公共分支:优先考虑 git revert,而不是 reset + force push
本题真正的技术内核是:
不要把 Git 的“撤销”理解成删除;它本质上是移动引用,并决定是否同步调整暂存区和工作区。
3.Stack Overflow 经典问题:如何删除本地和远程 Git 分支?¶
原问题标题:
How do I delete a Git branch locally and remotely?
题主场景可以概括为:
我想删除一个 Git 分支,既要删除本地分支,也要删除远程仓库里的分支。应该分别用什么命令?
这个问题的关键不是“删除一个文件夹”,而是要区分 Git 里不同位置的分支引用:
第一名答案总结¶
第一名答案给出的执行摘要是:
通常 <remote_name> 是:
所以最常见写法是:
也可以把远程删除命令写成更完整的形式:
第一名答案还补充:git branch -d 只会删除已经合并的本地分支;如果要强制删除本地分支,可以用 git branch -D <branchname>。同时,如果你正在当前分支上,Git 不允许你删除当前正在 checkout 的分支。(Stack Overflow)
命令逐行解析¶
1. 删除远程分支¶
等价于:
含义是:
它删除的是远程仓库中的:
也就是服务器端真正的远程分支。
注意,这里用的是 git push,不是 git branch。
原因是:
第一名答案也提到,旧语法还可以写成:
这个冒号语法含义比较晦涩,现代写法更推荐:
因为可读性更好。(Stack Overflow)
2. 删除本地分支¶
含义是:
它删除的是本地的:
Git 官方文档说明,git branch -d / --delete 用于删除分支;-d 要求该分支已经被合并到其 upstream,或者没有 upstream 时合并到 HEAD。(Git)
3. 强制删除本地分支¶
-D 等价于:
适用场景:
Git 官方文档也明确说明,-D 是 --delete --force 的快捷方式;--force 与 -d 组合时,会忽略 merged status 删除分支。(Git)
所以:
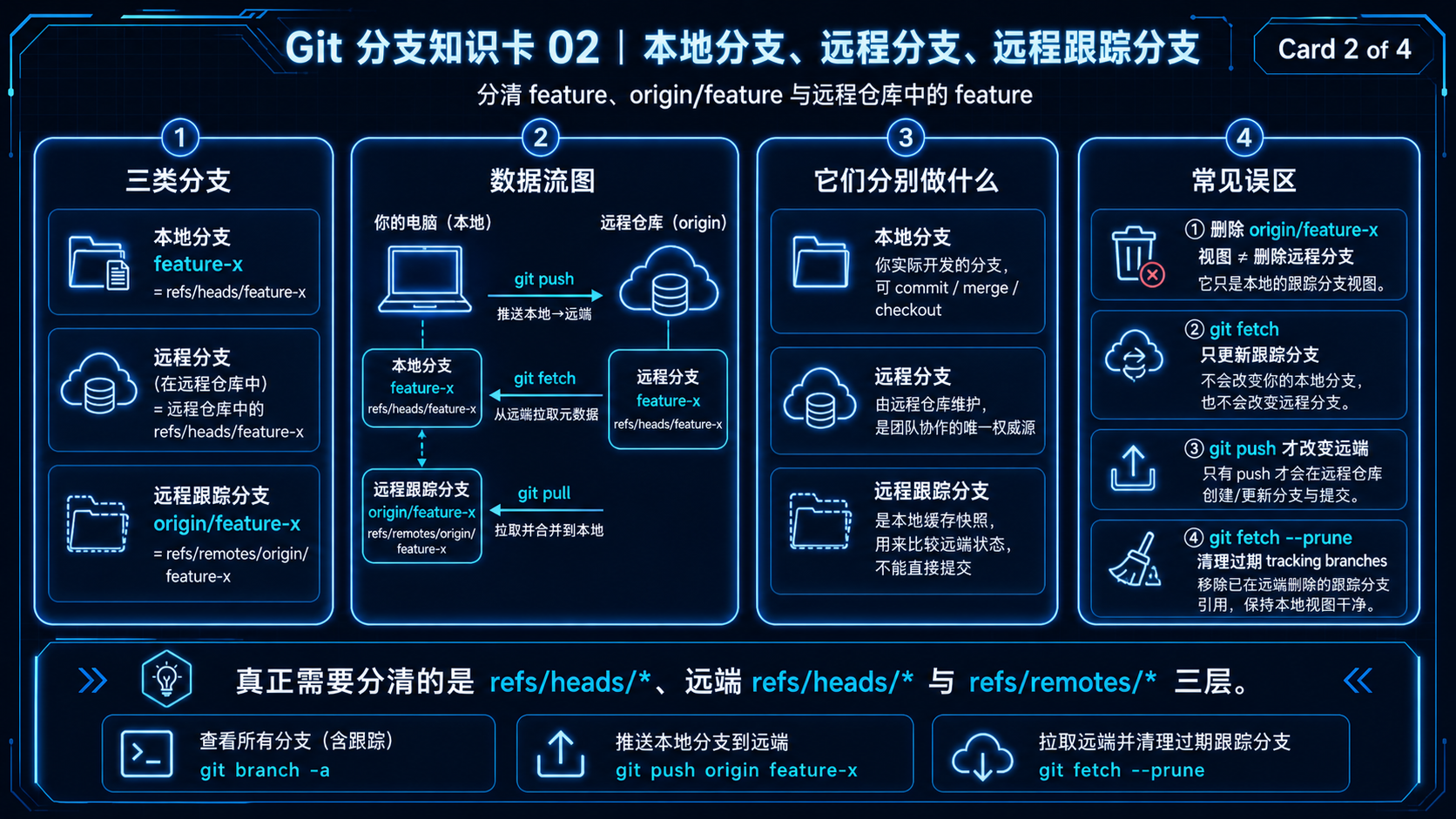
本地分支、远程分支、远程跟踪分支¶
这道题最容易混的地方在于:Git 里其实可能涉及三种“看起来像同一个名字”的分支。
假设分支名叫:
那么可能同时存在:
它们不是一回事。
1. 本地分支:feature-x¶
这是你本机真正可以 checkout、commit 的分支。
查看本地分支:
删除本地分支:
或强制删除:
2. 远程分支:远程仓库里的 feature-x¶
这是 GitHub、GitLab、Gitea 或其他远程仓库服务器上的分支。
删除远程分支:
或者:
它删除的是服务器上的分支,不是简单删除你本地的 origin/feature-x 显示项。
3. 远程跟踪分支:origin/feature-x¶
这是你本地保存的远程分支快照。
查看所有本地和远程跟踪分支:
查看远程跟踪分支:
远程分支被删除后,其他机器上可能还会看到过期的:
这时需要清理远程跟踪分支:
或者针对某个远程:
Stack Overflow 第一名答案评论区也提到,删除远程分支后,其他机器可用 git fetch --all --prune 清理过期的 remote-tracking branches。(Stack Overflow)
Git 官方文档也说明,可以用 git branch -r -d 删除 remote-tracking branch;但只有当它已经不在远程存在,或者 fetch 配置不会重新拉回时,这样做才有意义。(Git)
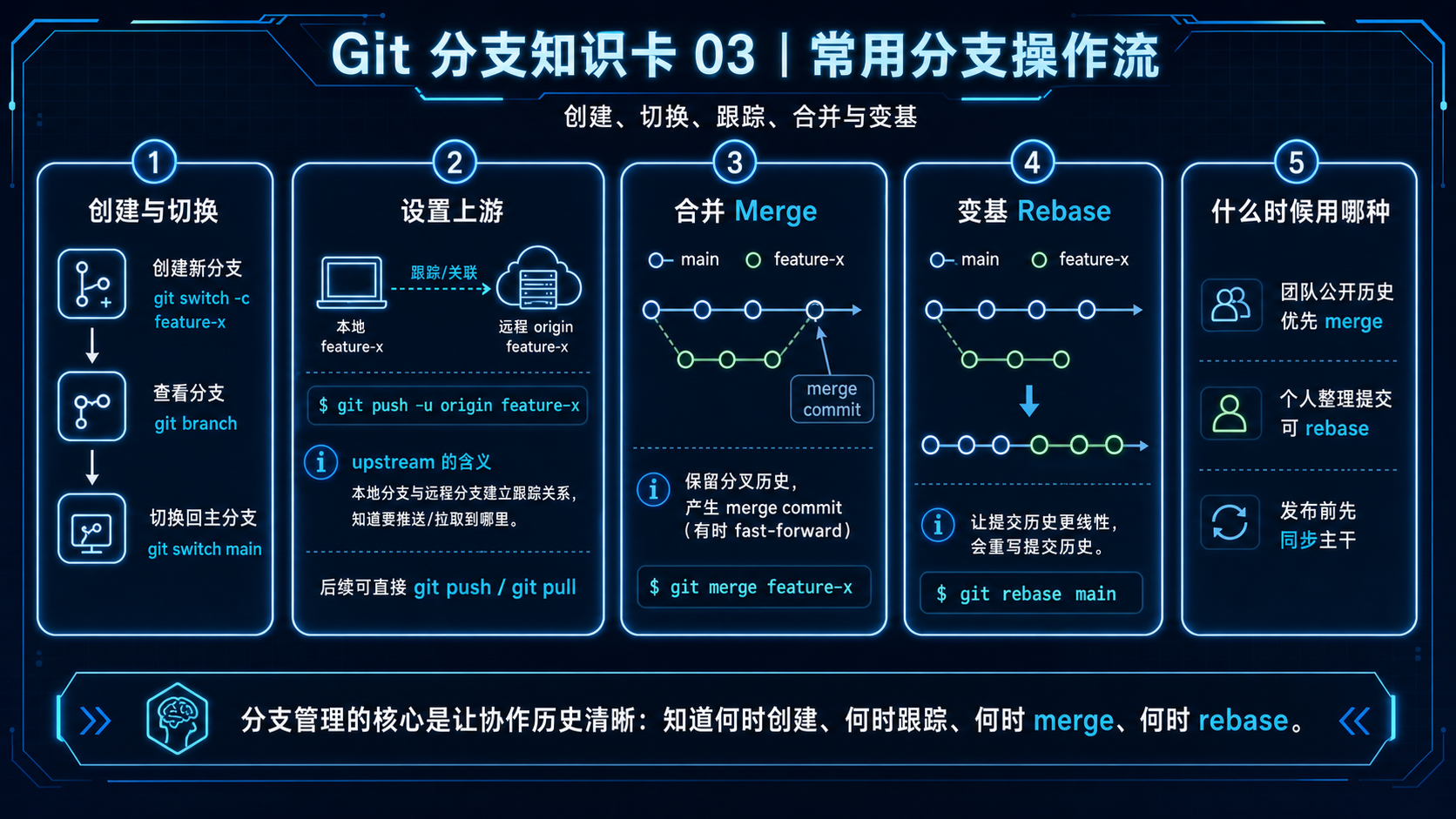
常见安全流程¶
假设要删除的分支是:
推荐流程是:
# 1. 先切到其他分支,不能站在要删除的分支上
git switch main
# 2. 确认本地分支
git branch
# 3. 删除远程分支
git push origin --delete feature-x
# 4. 删除本地分支
git branch -d feature-x
# 5. 如果 Git 提示未合并,但你确认不要了
git branch -D feature-x
# 6. 清理过期的远程跟踪分支
git fetch --prune
为什么不能删除当前分支?¶
如果你当前就在:
然后执行:
Git 通常会拒绝。
原因是:
因此需要先执行:
或者旧写法:
然后再删除:
-d 和 -D 的区别¶
| 命令 | 含义 | 是否检查已合并 | 风险 |
|---|---|---|---|
git branch -d feature-x |
安全删除本地分支 | 是 | 低 |
git branch -D feature-x |
强制删除本地分支 | 否 | 高 |
git push origin --delete feature-x |
删除远程分支 | 不等同于本地合并检查 | 中 |
git fetch --prune |
清理本地过期远程跟踪分支 | 不删除远程真实分支 | 低 |
原理精髓:删除分支就是删除引用¶
Git 分支本质上不是一整份代码副本,而是一个指向某个 commit 的引用。
例如:
删除本地分支:
本质上是删除:
而不是删除 A/B/C 这些 commit 对象本身。
只要这些 commit 还能被其他分支、tag 或 reflog 引用,它们通常仍然存在。
删除远程分支:
本质上是请求远程仓库删除:
删除远程跟踪分支:
本质上是清理本地已经过期的:
所以这道题真正要分清的是:
最关键的一句话¶
删除 Git 分支不是删除一份代码目录,而是删除某个分支引用;本地分支用 git branch -d/-D 删除,远程分支用 git push origin --delete 删除,过期的远程跟踪分支用 git fetch --prune 清理。
工程启示¶
这道题的精髓可以总结为:
实际使用中,推荐记住这组命令:
# 删除远程分支
git push origin --delete <branch>
# 删除本地分支,安全模式
git branch -d <branch>
# 删除本地分支,强制模式
git branch -D <branch>
# 清理过期远程跟踪分支
git fetch --prune
本题真正的技术内核是:
Git 的 branch 不是代码副本,而是 commit 引用;删除 branch,本质上是删除引用,而不是立即销毁所有 commit 数据。