Postgresql数据库调优
参考连接:
An Introduction to PostgreSQL Performance Tuning and Optimization
本文档介绍如何调整 PostgreSQL 和 EDB Postgres Advanced Server (EPAS)(版本 10 至 13)
所使用的系统是 RHEL 系列 linux version 8。这些只是一般指南,实际调整细节会因工作负载而异,但它们应能为大多数部署提供一个良好的起点。
调优时,我们从硬件开始,然后逐级向上,最后完成应用程序的 SQL 查询。
随着堆栈的不断升级,与工作负载相关的调优方面也会越来越高,因此我们会从最普通的方面开始,然后再到与工作负载最相关的方面
1. 规划机器¶
数据库部署的服务器类型如下:
bare metal 裸金属服务器
virtualized machines 虚拟机
containerized 容器化
- 本文档侧重裸金属和虚拟机
1.1 裸金属¶
在为 PostgreSQL 设计裸机服务器时,需要考虑一些因素。这些因素包括 CPU、内存、磁盘,少数情况下还包括网卡
1.1.1 CPU¶
选择合适的 CPU 可能是 PostgreSQL 性能的关键点。
在处理大型数据时,CPU 的速度(主频)很重要,但拥有更大 L3 高速缓存(吞吐量)的 CPU 也会提高性能。
对于OLTP性能,拥有更多更快的核心将有助于操作系统和PostgreSQL 更有效地利用这些内核资源。
另一方面,使用具有较大 L3 高速缓存的 CPU 对于较大的数据集也有好处。
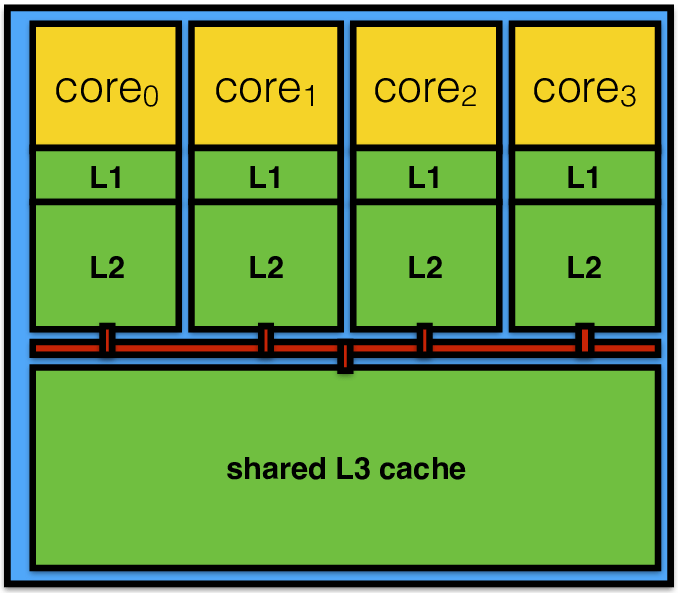
L3缓存是什么?
CPU 至少有两个缓存:L1(又称一级缓存)和 L2(又称二级缓存)。
L1 是最小、最快的缓存,嵌入在 CPU 内核中,存储数据结构和数据。
二级缓存比一级缓存稍慢,但也比一级缓存大。L2 用于为 L1 缓存提供数据,仅存储数据。
与每个内核独有的 L1 和 L2 高速缓存(又叫私有缓存,每个CPU核心有各自的缓存区域)不同,L3 高速缓存是内核之间共享的。与 L1 和 L2 缓存相比,L3 缓存的速度较慢,但它是由所有可用内核共享的。此外,请注意 L3 缓存仍然比 RAM 快,而且也是仅存储数据。
拥有更大的 L3 缓存可以在处理更多数据时提高 CPU 性能。这也有利于 PostgreSQL 的并行查询。
1.1.2 RAM¶
除了CPU,在其他硬件中最便宜,对 PostgreSQL 而言性能也更好。
操作系统倾向于利用可用内存,尽可能多地缓存数据。缓存越多,磁盘 I/O 就越少,查询速度就越快。
购买新硬件时,我们建议首先添加尽可能多的内存。
- 将来再增加内存,从财务和技术方面来说都会更昂贵(需要停机,除非你的系统有热插拔内存)。
根据可用内存,PostgreSQL 的多个参数会发生变化。3.2 资源利用
1.1.3 磁盘¶
如果应用程序是 I/O(读取和/或写入密集型),选择速度更快的磁盘将大大提高性能。有多种解决方案可供选择,包括 NMVe 和固态硬盘驱动器。
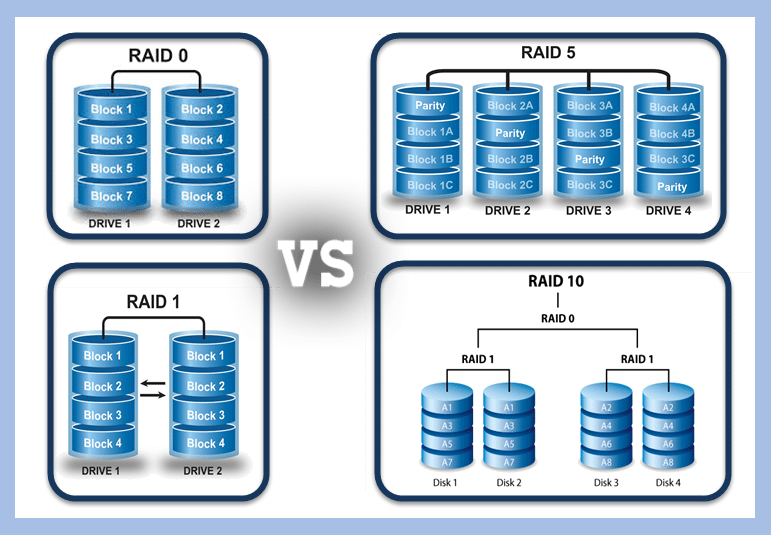
第一条经验法则是将 WAL 日志存放的磁盘与数据磁盘分开。WAL 可能会成为瓶颈(在写密集型数据库中),因此将 WAL 放在单独的快速驱动器上可以解决这个问题。始终至少使用 RAID 1(镜像),尽管在某些情况下,如果数据库的写入量确实很大,可能需要使用 RAID 1+0(镜像加条带化)。
数据库推荐raid10作为存储方案
磁盘阵列相关扩展
为索引和数据使用单独的表空间和驱动器也会提高性能,尤其是 PostgreSQL 在 SATA 硬盘上运行时。
SSD 和 NVMe 驱动器通常不需要这样做。我们建议对数据盘使用 RAID 10。
有关优化驱动器的更多信息,请参阅 优化文件系统部分。
此外,本博文还讨论了可与 PostgreSQL 一起使用的存储和 RAID 选项。
raid条带的block size 与磁盘分区对齐可以参考以下文章,这个在部署数据库的时候非常重要
1.1.4 网卡¶
尽管网卡看起来与 PostgreSQL 的性能无关,但当数据大量增长时,更快或绑定的网卡也会加快基础备份的速度。
1.2 虚拟机¶
与裸机服务器相比,虚拟机由于虚拟化层而存在性能缺陷,尽管目前虚拟机相对较小。
此外,由于共享资源,可用的CPU和磁盘I/O也会减少。
有一些技巧可以让 PostgreSQL 在虚拟机中获得更好的性能:有一些技巧则可以让 PostgreSQL 在虚拟机外获得更好的性能:
-
考虑将虚拟机固定到特定的 CPU 和磁盘。这将消除(或限制)由于主机上运行其他虚拟机而出现的性能瓶颈。
-
考虑在安装前预先分配磁盘空间。这样可以防止主机在数据库操作期间分配磁盘空间。
如果无法这样做,您可以在postgresql.conf中更改以下两个参数:
-
禁用 postgresql.conf 中的
wal_recycle参数。默认情况下,PostgreSQL 通过重命名 WAL 文件来回收它们。
但是,在写入时复制 (COW) 文件系统上创建新的 WAL 文,件可能会更快,因此禁用此参数将有助于虚拟机。
-
禁用 postgresql.conf 中的
wal_init_zero参数。默认情况下,WAL 空间是在插入 WAL 记录之前分配的。这将减慢 COW 文件系统上的 WAL 操作。
禁用此参数将禁用此功能,从而帮助虚拟机更好地执行。如果设置为关闭,则在创建文件时仅写入最后一个字节,以使其具有预期的大小。
2. 优化系统¶
说到 PostgreSQL 的性能,优化操作系统会给你带来更多提高性能的机会。
正如导言中所指出的,本指南侧重于为 Red Hat Enterprise Linux (RHEL) 系列调优 PostgreSQL。
2.1 优化守护进程¶
RHEL 上的大部分优化调整都是通过tuned守护进程完成的。该守护进程使操作系统能够更好地执行工作负载。
请注意,下面显示的命令适用于 RHEL 8。
如果您使用的是 RHEL 7,则应在示例中显示 dnf 的任何位置使用 yum 命令。
tuned 守护进程是默认安装的。如果没有(可能是由于 kickstart 文件的配置),请使用以下命令安装
dnf -y install tuned
# 或者
yum install tuned
接着将服务enable
- tuned 帮助系统管理员轻松动态地更改内核设置,并且他们不再需要在 /etc/sysctl 中进行更改 。
这一切都是通过tuned完成的
tuned 带有一些预定义的配置文件。您可以使用以下命令获取列表
(base) [root@oel7 ~]# tuned-adm list
Available profiles:
- balanced - General non-specialized tuned profile
- desktop - Optimize for the desktop use-case
- hpc-compute - Optimize for HPC compute workloads
- latency-performance - Optimize for deterministic performance at the cost of increased power consumption
- network-latency - Optimize for deterministic performance at the cost of increased power consumption, focused on low latency network performance
- network-throughput - Optimize for streaming network throughput, generally only necessary on older CPUs or 40G+ networks
- powersave - Optimize for low power consumption
- throughput-performance - Broadly applicable tuning that provides excellent performance across a variety of common server workloads
- virtual-guest - Optimize for running inside a virtual guest
- virtual-host - Optimize for running KVM guests
Current active profile: virtual-guest
RHEL 安装程序将根据环境选择合适的默认值。裸机默认是吞吐量-性能,旨在提高吞吐量。
您可以运行以下命令来查看tuned守护进程在评估您的系统后会推荐什么
(base) [root@oel7 ~]# tuned-adm recommend
virtual-guest
使用以下命令查看预配置的值
(base) [root@oel7 ~]# tuned-adm active
Current active profile: virtual-guest
然而,默认设置最终可能会减慢 PostgreSQL 的速度——它们可能更倾向于省电,这会减慢 CPU 的速度。
类似的论点也适用于网络和 I/O 调整。为了解决这个问题,我们将为 PostgreSQL 性能创建自己的配置文件。
创建新的配置文件非常容易。我们将此配置文件称为edbpostgres。
以 root 身份运行这些命令
(base) [root@oel7 ~]# mkdir /etc/tuned/edbpostgres
(base) [root@oel7 ~]#
(base) [root@oel7 ~]# echo "
> [main]
> summary=Tuned profile for EDB PostgreSQL Instances
> [bootloader]
> cmdline=transparent_hugepage=never
> [cpu]
> governor=performance
> energy_perf_bias=performance
> min_perf_pct=100
> [sysctl]
> vm.swappiness = 10
> vm.dirty_expire_centisecs = 500
> vm.dirty_writeback_centisecs = 250
> vm.dirty_ratio = 10
> vm.dirty_background_ratio = 3
> vm.overcommit_memory=0
> net.ipv4.tcp_timestamps=0
>
> [vm]
> transparent_hugepages=never
> " > /etc/tuned/edbpostgres/tuned.conf
在中括号[]之间的部分称为tuned 插件,用于与系统的给定部分进行交互
我们检查一下这些参数和值:
-
[main] 插件包含摘要信息,也可用于通过 include 语句包含来自其他已调整配置文件的值(类似mysql的conf文件,有个域的概念)
-
[cpu] 插件包括 CPU 调速器的设置和 CPU 功率设置
-
[sysctl] 插件包含与 procfs(进程文件系统) 交互的值。
-
[vm] 和 [bootloader] 插件启用/禁用透明的大页面(bootloader 插件将帮助我们与 GRUB 命令行参数进行交互)
通过以上部分调整,我们需要达到以下目标:
-
CPU 不会进入省电模式(PostgreSQL 不会出现随机性能下降的情况)
-
Linux 更倾向于不适用交换分区
SWAP -
内核将帮助Postgres刷新脏页,减少
bgwriter和checkpointer进程的负载 -
pdflush 守护进程将更频繁地运行
-
关闭 TCP 时间戳是一个很好的做法,以避免(或至少减少)由时间戳生成引起的峰值。
-
禁用透明大页对 PostgreSQL 性能有很大好处。
若要启用这些更改,请运行以下命令:
(base) [root@oel7 ~]# tuned-adm profile edbpostgres
要完全禁用透明大页,请运行此命令
(base) [root@oel7 ~]# grub2-mkconfig -o /boot/grub2/grub.cfg
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-3.10.0-1160.53.1.el7.x86_64
Found initrd image: /boot/initramfs-3.10.0-1160.53.1.el7.x86_64.img
Found linux image: /boot/vmlinuz-3.10.0-1160.49.1.el7.x86_64
Found initrd image: /boot/initramfs-3.10.0-1160.49.1.el7.x86_64.img
Found linux image: /boot/vmlinuz-3.10.0-1160.45.1.el7.x86_64
Found initrd image: /boot/initramfs-3.10.0-1160.45.1.el7.x86_64.img
Found linux image: /boot/vmlinuz-0-rescue-21acf41b46a64ca4a55e93cb350a7749
Found initrd image: /boot/initramfs-0-rescue-21acf41b46a64ca4a55e93cb350a7749.img
Found linux image: /boot/vmlinuz-0-rescue-c69b252634034e98971c95f82adee103
Found initrd image: /boot/initramfs-0-rescue-c69b252634034e98971c95f82adee103.img
done
并重新启动系统:
systemctl start reboot.target
关于透明大页
2.2 优化文件系统¶
另一个调整点是磁盘。
PostgreSQL 的数据文件不依赖 atime(文件最后一次被访问的时间戳),因此禁用它们可以节省 CPU 周期。
打开 /etc/fstab,在保存 PostgreSQL 数据和 WAL 文件的驱动器的默认值附近添加 noatime。
/dev/mapper/pgdata-01-data /pgdata xfs ext4 defaults,noatime 1 1
若要立即激活它,请运行:
mount -o remount,noatime,nodiratime /pgdata
- 请注意,这些建议是好的开始,您需要同时监控操作系统和 PostgreSQL 以收集更多数据以进行更精细的调整。
2.3 大页¶
默认情况下,Linux 上的页面大小为 4kB。
典型的 PostgreSQL 实例可能会分配许多 GB 的内存,这最终会导致如此小的页面大小带来潜在的性能问题。
此外,鉴于这些页面将是碎片化的,将它们用于大型数据集最终将有额外的时间来映射它们。
在 Linux 上启用大页面将提高 PostgreSQL 的性能,因为它将同时分配大块(大页面)内存。
postgresql举例 为什么大页对数据库系统而言非常重要
大页面会减少虚拟内存机制中多级映射的层数,减少资源浪费,加速操作
大页面一般不会被驱逐,这点是非常重要的,这会带来可预期的稳定的性能
默认情况下,Linux 上不启用大页面,这也适用于 PostgreSQL 的默认huge_pages设置,即try,这基本上意味着“如果操作系统上可用,请使用大页面,否则不使用。
为 PostgreSQL 设置大页面有两个方面:配置操作系统和配置 PostgreSQL。
-
让我们首先找出 PostgreSQL 系统上需要多少个大页面。启动 PostgreSQL 实例时,postmaster 会在 $PGDATA中创建一个名为 postmaster.pid file 的文件。您可以在那里找到主进程的 pid:
-bash-4.2$ head -n 1 $PGDATA/postmaster.pid 27382 -
现在,找到此实例的 VmPeak:
-bash-4.2$ grep -i vmpeak /proc/27382/status VmPeak: 1350328 kB- 提示:如果您在同一台服务器上运行多个 PostgreSQL 实例,请在下一步中计算所有 VmPeak 值的总和。
-
让我们确认一下大页大小
-bash-4.2$ grep -i hugepagesize /proc/meminfo Hugepagesize: 2048 kB -
最后,让我们计算实例需要的大页面数:
huge\page\num = Vmpeak/Hugepagesize
1350328/2048 = 659
- 理想的大页面数量仅比这高一点——只是一点点。
如果增加此值过多,则需要小页面的进程将无法启动,而这些小页面也需要操作系统中的空间。
这甚至可能最终导致操作系统无法启动或同一服务器上的其他 PostgreSQL 实例无法启动。
-
现在编辑上面创建的 tuned.conf 文件,并将以下行添加到 [sysctl] 部分:
vm.nr_hugepages= 659行以下命令以启用新设置
tuned-adm profile edbpostgres -
配置postgresql.conf中的
huge_pages项huge_pages=on -
我们还需要确保在重新启动后,调整后的服务将在 PostgreSQL 服务之前启动。编辑systemd单元文件:
systemctl edit postgresql-13.service # 增加以下两行 [Unit] After=tuned.service保存后重载
systemctl daemon-reload
3. PostgreSQL调试起点¶
以下配置选项是通常应从 PostgreSQL 中的默认值更改的选项。
其他值可能会对性能产生重大影响,但此处不讨论,因为它们的默认值已被视为最佳值。
postgresql参数调优可以以下两个网站给出了参考建议
3.1 配置和认证¶
3.1.1 max_connections¶
max_connections 的最佳数量大约是 CPU 内核数的 4 倍。
这个公式通常给出一个非常小的数字,不会留下太多出错的余地。推荐的数字是 GREATEST(4 \times CPU\cores, 100)。
超过此数字,应使用连接池程序,例如 pgbouncer。
重要的是要避免max_connections设置得太高,因为它会增加 Postgres 中各种数据结构的大小,从而导致 CPU 周期被浪费。
相反,我们还需要确保分配足够的资源来支持所需的工作负载。
3.1.2 password_encryption¶
认证方式一般默认为md5,但是安全性不足,pg12版本之后,增加了scram-sha-256加密认证,推荐。
3.2 资源利用¶
3.2.1 shared_buffers¶
此参数的变化最大。
某些工作负载在使用非常小的值(例如 1GB 或 2GB)时效果最佳,即使数据库卷非常大也是如此。
其他工作负载需要较大的值。一个合理的起点是 LEAST(RAM/2, 10GB)。
- 官方的推荐是
RAM / 4
除了PostgreSQL社区多年的集体智慧和经验之外,这个公式没有具体的原因。内核缓存和 shared_buffers 之间存在复杂的交互,因此几乎不可能准确描述为什么此公式通常提供良好的结果。
3.2.2 work_mem¶
work_mem的推荐起点是 ((Total\ RAM - shared\buffers)/(16 \times CPU cores))。
这个公式背后的逻辑是,如果你有太多的查询,你可能会耗尽内存,那么你已经受到 CPU 的限制;
这个公式为一般情况提供了一个相对较大的限制。
将work_mem设置为更高的值可能很诱人,但应避免这种情况,因为此处指定的内存量可能由单个查询计划中的每个节点使用,因此单个查询可能总共使用多个work_mem,例如在嵌套的哈希联接字符串中。
3.2.3 maintenance_work_mem¶
这决定了用于维护操作(如 VACUUM、CREATE INDEX、ALTER TABLE、ADD FOREIGN KEY 和数据加载操作)的最大内存量。
在执行此类活动时,这些操作可能会增加数据库服务器上的 I/O,因此为它们分配更多内存可能会导致这些操作更快地完成。
值 1GB 是一个好的开始,因为这些命令是由 DBA 显式运行的。(手动session 级别),例如
begin;
set local maintenance_work_mem = '4GB';
create index xxx
...
commit;
autovacuum_work_mem
将 maintenance_work_mem 设置为较高的值还将允许 autovacuum 工作人员每人使用那么多内存。
vacuum worker 为要清理的每个死元组使用 6 个字节的内存,因此仅 8MB 的值将允许大约 140 万个死元组。
3.2.4 effective_io_concurrency¶
该参数用于在某些操作期间进行预读取read-ahead,并应设置为用于存储数据的磁盘数量。
它最初旨在帮助 Postgres 了解在使用旋转磁盘的条带化 RAID 阵列时可能并行发生多少次并行读取,然而,通过使用该数字的倍数已经观察到改进,这可能是由于高质量的 RAID 适配器可以重新排序和流水线请求以提高效率。
对于 SSD 磁盘,建议将此值设置为 200
主要是对顺序扫描和位图扫描影响较大
linux 预读与 postgresql effective_io_concuurency
3.3 日志预写入 WAL¶
3.3.1 wal_compression¶
当此参数打开时,PostgreSQL 服务器会在 full_page_writes 打开或基础备份期间压缩写入 WAL 的整页映像。
将此参数设置为on,因为大多数数据库服务器可能在 I/O 而不是 CPU 上遇到瓶颈。
3.3.2 wal_log_hints¶
要使用 pg_rewind,此参数是必需的。将其设置为on。
3.3.3 wal_buffers¶
这控制了后端在内存中写入 WAL 数据的可用空间量,以便 WALWriter 可以在后台将其写入磁盘上的 WAL 日志。
默认情况下,WAL段默认为16MB,因此缓冲一个段在内存开销方面是非常廉价的
据观察,较大的WAL缓冲区大小对测试性能有潜在的非常积极的影响。将此参数设置为 64MB。
3.3.4 checkpoint_timeout¶
较长的超时会减少整体 WAL 量,但会使崩溃恢复需要更长的时间。建议的值至少为 15 分钟,但最终,业务需求的 RPO 决定了这个值应该是什么。
PRO(Recovery Point Objective)和 RTO(Recovery Time Objective)是两个关键的恢复指标,通常用于规划和评估业务连续性和灾难恢复计划。它们在信息技术和数据管理领域中经常被用于确保组织能够在面临各种灾难和数据丢失情况下快速而有效地恢复。
Recovery Point Objective (RPO) - 恢复点目标:
定义: RPO 衡量在灾难或系统故障发生时,组织可以接受的数据丢失程度。
解释: RPO 表示一个组织愿意丢失的最大时间窗口内的数据。如果在灾难发生前的最后一个备份发生在 RPO 时间窗口之前,那么组织就有可能丢失在这段时间内所做的所有更改。
例子: 如果某个组织的 RPO 设置为 1小时,那么在发生灾难时,他们最多可以接受丢失 1 小时的数据。
Recovery Time Objective (RTO) - 恢复时间目标:
定义: RTO 衡量在灾难或系统故障发生时,组织需要多长时间来恢复业务功能。
解释: RTO 是指从灾难发生到系统或业务功能完全恢复所需的时间。它是业务在中断期间可以容忍的最长停机时间。
例子: 如果某个组织的 RTO 设置为 4 小时,那么在灾难发生后,他们的目标是在 4 小时内将业务功能完全恢复。

3.3.5 checkpoint_completion_target¶
这决定了 PostgreSQL 旨在完成检查点的时间。
这意味着检查点不需要导致 I/O 峰值,而是旨在将写入分散到checkpoint_timeout值的这一部分上。
建议的值为 0.9(将成为 PostgreSQL 14 中的默认值)。
3.3.6 max_wal_size¶
检查点应始终由超时触发,以获得可预期的稳定的性能和可预测性。
这个可以通过系统视图观察检查点的情况。
postgres=# select * from pg_stat_bgwriter;
-[ RECORD 1 ]---------+------------------------------
checkpoints_timed | 115812
checkpoints_req | 21
checkpoint_write_time | 5382552
checkpoint_sync_time | 1482
buffers_checkpoint | 460545
buffers_clean | 29861
maxwritten_clean | 291
buffers_backend | 518867
buffers_backend_fsync | 0
buffers_alloc | 555181
stats_reset | 2022-11-22 13:55:27.646887+08
-
checkpoints_timed 检查点到时后被调起刷盘的次数
-
checkpoints_req 超过max_wal_size,被动的被唤起刷盘的次数
⚠️检查点触发的几个条件
1.checkpoint_timeout 设置的间隔时间自上一个检查点已经过去(默认间隔为 300 秒(5 分钟))。
2.在 9.4 或更早版本中,为checkpoint_segments设置的 WAL 段文件的数量自上一个检查点以来已经被消耗(默认数量为 3)。
3.在 9.5 或更高版本中,pg_xlog(在 10 或更高版本中为 pg_wal)中的 WAL 段文件的总大小已超过参数max_wal_size的值(默认值为 1GB(64 个文件))。
4.PostgreSQL 服务器在smart或fast模式下停止。
5.当超级用户手动发出 CHECKPOINT 命令时,它的进程也会这样做。
6.写入WAL的数据量已达到参数max_wal_size(默认值:1GB)
7.执行pg_start_backup函数时
8.在进行数据库配置时(例如CREATE DATABASE / DROP DATABASE语句)
应使用 max_wal_size 参数来防止磁盘空间不足,方法是确保在达到此值时发生检查点,以使 WAL 能够被回收。
建议的值是 WAL 所在可用磁盘空间的一半到三分之二。
- wal日志有膨胀和堆积的风险,WAL日志如果单独存储在专门的磁盘驱动上,需要注意
⚠️wal日志膨胀的原因
3.3.7 archive_mode¶
由于更改此设置需要重新启动,因此应将其设置为on,除非您知道永远不会使用 WAL 存档。
- 生产系统必须开启归档日志
3.3.8 archive_command¶
如果archive_mode处于打开状态,则需要有效的archive_command。
在准备好配置存档之前,建议使用默认值 ': to be configured'。
':' 原语只是在 POSIX 系统(包括 Windows)上返回成功,告诉 Postgres 可以回收或删除 WAL 段。“待配置”是一组将被忽略的参数。
3.4 查询优化¶
3.4.1 random_page_cost¶
此参数为 PostgreSQL 优化器提供了有关从磁盘读取随机页面的成本的系数,使其能够决定何时使用索引扫描与顺序扫描。
如果使用 SSD 磁盘,建议的值为 1.1。
对于旋转磁盘,默认值通常就足够了。
此参数应全局设置并按表空间设置。(如果磁带机上有一个包含历史数据的表空间,则可能需要将此值设置得非常高,以阻止随机访问;顺序扫描和过滤器可能比使用索引更快。)
3.4.2 effective_cache_size¶
应该设置为较小的值,即 0.75* 总 ram 量,或 free 命令输出中 buff/cache、free ram 和共享缓冲区的总和,并用于向 PostgreSQL 提供有关其可用的总缓存空间的提示。
- 请注意,这是指主内存中的缓存,而不是 CPU 缓存。
-bash-4.2$ free -m
total used free shared buff/cache available
Mem: 15884 2300 226 3426 13358 10020
Swap: 4095 4 4091
在此示例中,effective\cache\size =least (15884 \times 0.75, 226+ 13358 + 8192)
(假设 shared_buffers 为 8GB,因此为 11913MB。11913
3.4.3 cpu_tuple_cost¶
指定在查询过程中处理每一行的相对开销。
它的默认值是 0.01,但这可能低于最佳值,经验表明,它通常应该增加到 0.03,以获得更现实的开销。
3.5 报告和审计日志¶
3.5.1 logging_collector¶
如果包含 stderr 或 csvlog 以将输出收集到日志文件中log_destination则此参数应为 on。
3.5.2 log_directory¶
如果logging_collector处于打开状态,则应将其设置为数据目录之外的位置。这样,日志就不是基本备份的一部分.
- 保持数据目录的纯粹非常重要,像归档日志,审计日志,以及其他的逻辑备份等,都不应当和数据文件放在一起。
3.5.3 log_checkpoints¶
出于将来的诊断目的,应将其设置为 on,特别是验证检查点是否按checkpoint_timeout而不是按max_wal_size发生。
3.5.4 log_line_prefix¶
这定义了日志文件中行前的前缀的格式。
前缀应至少包含时间、进程 ID、行号、用户和数据库以及应用程序名称,以帮助进行诊断。
建议值: '%m [%p-%l] %u@%d app=%a '
3.5.5 log_lock_waits¶
设置为 on。此参数在诊断慢速查询时是必不可少的
3.5.6 log_statement¶
设置为ddl。除了留下基本的审计跟踪外,这将有助于确定灾难性人为错误发生的时间,例如删除错误的表。
- 如果需要,设置成mod也可以,对数据库对象的所有变动进行记录
3.5.7 log_temp_files¶
设置为 0。这将记录创建的所有临时文件,表明work_mem未正确调整。
3.5.8 timed_statistics (EPAS)¶
控制动态运行时检测工具体系结构 (DRITA) 功能的计时数据的收集。设置为 on 时,将收集计时数据。将此参数设置为 on。
3.6 自动清理¶
3.6.1 log_autovacuum_min_duration¶
监视 autovacuum 活动将有助于对其进行调整。建议值:0,将记录所有 autovacuum 活动。
3.6.2 autovacuum_max_workers¶
这是 autovacuum 拥有的worker数量。缺省值为 3,需要重新启动数据库服务器才能更新。
请注意,每张表只能有一个worker在运行,因此增加worker只能帮助并行且更频繁地清理表。
默认值较低,因此建议将此值增加到 5 作为起点。
3.6.3 autovacuum_vacuum_cost_limit¶
为了防止由于自动真空而导致数据库服务器上的负载过大,Postgres 施加了 I/O 配额。
每次读/写都会导致此配额耗尽,一旦耗尽,autovacuum 进程就会休眠固定时间。
此配置增加了配额限制,从而增加了真空可以执行的 I/O 量。
默认值为低,建议将此值增加到 3000。
3.7 客户端限制¶
3.7.1 idle_in_transaction_session_timeout¶
在事务中保持空闲状态的会话可以保持锁定并防止清理。
此计时器将终止在事务中保持空闲时间过长的会话,因此应用程序必须准备好从此类弹出中恢复。
3.7.2 lc_messages¶
日志分析器只能识别未翻译的消息。将其设置为C以避免翻译。
3.7.3 shared_preload_libraries¶
增加pg_stat_statements插件。
开销低,价值高。这是建议的,但可选(见下文)。
4. 基于负载分析进行调优¶
4.1 慢查询¶
主要有以下几种查找慢查询的方法:
-
log_min_duration_statement参数
-
pg_stat_statements模块和扩展
log_min_duration_statement 参数是一个查询时间设置(粒度毫秒),计算查询在发送到日志文件之前必须运行多长时间。
若要获取所有查询,请将其设置为 0,但请注意:这可能会导致相当多的 I/O!
通常,将其设置为“1s”(一秒),然后按如下所述优化所有查询。
然后,逐渐降低开销并重复该过程,直到达到合理的阈值,然后在那里进行持续优化。什么是合理的阈值完全取决于您的工作负载,无法在像本文档这样的通用文档中定义。
这是查找慢速查询的好方法,但它不是最好的。
假设您有一个查询,执行时间为 1 分钟,并且每 10 分钟运行一次。现在,您有一个查询,该查询需要 20 毫秒才能执行,但每秒运行 20 次。优化哪个更重要?
规范化为 10 分钟,第一个查询占用服务器 1 分钟的时间,第二个查询总共需要 4 分钟。
因此,第二个比第一个更重要,但它可能会在您的log_min_duration_statement雷达下飞行(无法捕获)。
进入pg_stat_statements模块。这样做的一个缺点是它需要在shared_preload_libraries中设置,这需要重新启动数据库实例服务。
幸运的是,它的开销非常低,回报如此之高,因此我们建议始终将其安装在生产环境中。
该模块的作用是记录服务器执行的每个(已完成的)查询,以各种方式对其进行规范化,例如用参数替换常量,然后将“相同”查询聚合到一个数据点中,其中包含有趣的统计信息,例如总执行时间、调用次数、最大和最小执行时间、返回的总行数、 创建的临时文件的总大小等等。
如果两个查询在分析后的规范化内部结构相同,则认为它们是“相同的”。
所以 SELECT * FROM t WHERE pk = 42; 是与 SeLeCt * FrOm T wHeRe Pk=56 相同的查询;尽管PK字段的值不同。
为了查看 pg_stat_statements 模块收集的统计信息,您首先需要安装插件
CREATE EXTENSION pg_stat_statements;
这将创建一个pg_stat_statements视图。
关于安全性的一句话。该模块从对服务器的所有查询中收集统计信息,而不管这些查询是针对哪个用户/数据库组合运行的。
该扩展可以安装在任何数据库中,如果需要,甚至可以安装在多个数据库中。
默认情况下,任何用户都可以从视图中进行select,但他们仅限于查询(与pg_stat_activity视图相同)。
超级用户和被授予 pg_read_all_stats 或 pg_monitor 角色的用户可以看到所有内容。
4.2 重写查询¶
有时,重写查询的某些部分可以大大提高性能。
4.3 裸字段¶
一个非常常见的错误是写这样的东西
SELECT * FROM t
WHERE t.a_timestamp + interval '3 days' < CURRENT_TIMESTAMP
应该替换为
SELECT * FROM t
WHERE t.a_timestamp < CURRENT_TIMESTAMP - interval '3 days'
这两句的查询结果是一样的,语义上没有什么不同,但是第二个可以使用索引,但是第一个则不能。
总体而言,保持字段干净naked column 在等式左侧,而把所有的表达式放在右侧
4.4 切勿在子查询中使用 NOT IN¶
IN作为谓词有两种形式出现:
x in (a,b,c)
x in (select ....)
对于正向查找的版本,你可以使用其中任意一个(两者可以互换)
对于反向版本,只能使用前者,即 x not in (a,b,c),原因在于处理空值
举例:
demo=# select 1 in (1, 2);
?column?
----------
t
(1 row)
demo=# select 1 in (1, null);
?column?
----------
t
(1 row)
demo=# select 1 in (2, null);
?column?
----------
(null)
(1 row)
这表明,在存在空值的情况下,IN 谓词只会返回 true 或 null,而绝不会返回 false。
由此可见,NOT IN 只返回 false 或 null,绝不会返回 true!
当给出这样一个常量列表时,很容易发现其中存在空值,从而知道查询永远不会得到想要的结果。
但如果使用子查询版本,就不那么容易发现了。更重要的是,即使子查询的结果保证没有空值,Postgres 也不会将其优化为反连接。
所以请使用 NOT EXISTS 代替not in (select x from yyy)。
4.5 EXPLAIN(analyze,buffers)¶
如果您的查询从未终止(至少在您失去耐心并放弃之前),那么您应该联系专家或自己成为专家,研究简单的 EXPLAIN 计划。在所有其他情况下,您必须始终使用 ANALYZE 选项来优化查询。
⚠️补充explain 节点介绍
⚠️补充深入学习各类索引的数据结构
4.6 错误的统计信息¶
错误的统计信息和糟糕的开销估算往往会误导pg系统做出错误的执行计划。
如果表的统计信息不是最新的,Postgres 可能会预测只返回两条记录,而实际上会返回 200 条记录。
对于一次扫描来说,这并不重要;扫描所需的时间会比预测的长一些,但仅此而已。
真正的问题在于蝴蝶效应。如果 Postgres 认为一次扫描会产生两条记录,它可能会选择嵌套循环对其进行连接。
当得到 200 条记录时,查询速度就会很慢;如果知道会有这么多记录,它就会选择散列连接或合并连接。
使用 ANALYZE 更新统计数据可以解决问题。
另外,您可能有规划器不知道的强相关数据。
您可以使用 CREATE STATISTICS 来解决这个问题。
⚠️ 增加手动新增统计信息相关操作
4.7 外部排序¶
如果排序操作没有足够的 work_mem,Postgres 就会将数据溢出到磁盘(临时表空间)。
由于内存比磁盘(甚至是 SSD)快得多,这可能会导致查询速度变慢。如果出现这种情况,请考虑增加 work_mem参数项
demo=# create table t (c bigint);
CREATE TABLE
demo=# insert into t select generate_series(1, 1000000);
INSERT 0 1000000
demo=# explain (analyze on, costs off) table t order by c;
QUERY PLAN
----------------------------------------------------------------------
Sort (actual time=158.066..245.686 rows=1000000 loops=1)
Sort Key: c
Sort Method: external merge Disk: 17696kB
-> Seq Scan on t (actual time=0.011..51.972 rows=1000000 loops=1)
Planning Time: 0.041 ms
Execution Time: 273.973 ms
(6 rows)
demo=# set work_mem to '100MB';
SET
demo=# explain (analyze on, costs off) table t order by c;
QUERY PLAN
----------------------------------------------------------------------
Sort (actual time=183.841..218.555 rows=1000000 loops=1)
Sort Key: c
Sort Method: quicksort Memory: 71452kB
-> Seq Scan on t (actual time=0.011..56.573 rows=1000000 loops=1)
Planning Time: 0.043 ms
Execution Time: 243.031 ms
(6 rows)
由于数据集较小,这里的差异并不明显。真实世界的查询可能会更明显。有时,就像这里的情况一样,最好添加一个索引来完全避免排序。
为防止病态、失控查询,请设置 temp_file_limit 参数。如果查询在临时文件中产生了如此多的数据,则查询会自动取消
4.8 哈希批次¶
另一个表明 work_mem 设置过低的指标是散列操作是否分批进行。
在下一个示例中,我们在运行查询前将 work_mem 设置为最低。然后重新设置,再次运行查询以比较计划。
demo=# create table t1 (c) as select generate_series(1, 1000000);
SELECT 1000000
demo=# create table t2 (c) as select generate_series(1, 1000000, 100);
SELECT 10000
demo=# vacuum analyze t1, t2;
VACUUM
demo=# set work_mem to '64kB';
SET
demo=# explain (analyze on, costs off, timing off)
demo-# select * from t1 join t2 using (c);
QUERY PLAN
------------------------------------------------------------------
Gather (actual rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Hash Join (actual rows=3333 loops=3)
Hash Cond: (t1.c = t2.c)
-> Parallel Seq Scan on t1 (actual rows=333333 loops=3)
-> Hash (actual rows=10000 loops=3)
Buckets: 2048 Batches: 16 Memory Usage: 40kB
-> Seq Scan on t2 (actual rows=10000 loops=3)
Planning Time: 0.077 ms
Execution Time: 115.790 ms
(11 rows)
demo=# reset work_mem;
RESET
demo=# explain (analyze on, costs off, timing off)
demo-# select * from t1 join t2 using (c);
QUERY PLAN
------------------------------------------------------------------
Gather (actual rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Hash Join (actual rows=3333 loops=3)
Hash Cond: (t1.c = t2.c)
-> Parallel Seq Scan on t1 (actual rows=333333 loops=3)
-> Hash (actual rows=10000 loops=3)
Buckets: 16384 Batches: 1 Memory Usage: 480kB
-> Seq Scan on t2 (actual rows=10000 loops=3)
Planning Time: 0.081 ms
Execution Time: 63.893 ms
(11 rows)
只做一个批次,执行时间就缩短了一半。
4.9 堆表读取¶
对于运行查询的事务来说,某一行是否可见,存储在表中该行本身。(pg的MVCC特性,事务可见性信息维护在堆表上)
可见性映射是一个位图,表示页面上的所有行是否对所有事务可见。
因此,索引扫描在找到匹配行时必须检查表(此处也称为堆),以确定找到的行是否可见。
仅索引扫描会使用可见性映射,尽可能避免从堆中获取记录。
如果可见性映射表明页面上并非所有记录都可见,那么本应是仅索引扫描的操作最终会导致 I/O 增加。最糟糕的情况是,它完全变成了普通的索引扫描。
执行计划会显示,由于可见性映射不是最新的,它不得不提交了多少次。
demo=# create table t (c bigint)
demo-# with (autovacuum_enabled = false);
CREATE TABLE
demo=# insert into t select generate_series(1, 1000000);
INSERT 0 1000000
demo=# create index on t (c);
CREATE INDEX
demo=# analyze t;
ANALYZE
demo=# explain (analyze on, costs off, timing off, summary off)
demo-# select c from t where c <= 2000;
QUERY PLAN
---------------------------------------------------------------
Index Only Scan using t_c_idx on t (actual rows=2000 loops=1)
Index Cond: (c <= 2000)
Heap Fetches: 2000
(3 rows)
理想情况下,这个值为零,但这取决于表的活动情况。
如果您经常修改和查询相同的页面,那么这里(Heap Fetches)就会显示出来。
如果情况并非如此,则意味着需要更新可见性映射。这需要通过vacuum来完成(这也是我们在本演示中关闭auto vacuum的原因)。
demo=# vacuum t;
VACUUM
demo=# explain (analyze on, costs off, timing off, summary off)
demo-# select c from t where c <= 2000;
QUERY PLAN
---------------------------------------------------------------
Index Only Scan using t_c_idx on t (actual rows=2000 loops=1)
Index Cond: (c <= 2000)
Heap Fetches: 0
(3 rows)
4.10 有损位图扫描¶
当数据分散在各个地方时,Postgres 会进行所谓的位图索引扫描。
它会建立一个位图,显示找到的每条匹配记录的页面和页面内的偏移量。
然后扫描表(堆),只需对每一页取一次,就能获得所有记录。
也就是说,如果它有足够的工作内存的话。
如果没有,它就会 "忘记 "偏移量,只记得页面上至少有一条匹配的记录。
堆扫描必须检查所有行,并过滤掉不匹配的行。
demo=# create table t (c1, c2) as
demo-# select n, n::text from generate_series(1, 1000000) as g (n)
demo-# order by random();
SELECT 1000000
demo=# create index on t (c1);
CREATE INDEX
demo=# analyze t;
ANALYZE
demo=# explain (analyze on, costs off, timing off)
demo-# select * from t where c1 <= 200000;
QUERY PLAN
------------------------------------------------------------------
Bitmap Heap Scan on t (actual rows=200000 loops=1)
Recheck Cond: (c1 <= 200000)
Heap Blocks: exact=5406
-> Bitmap Index Scan on t_c1_idx (actual rows=200000 loops=1)
Index Cond: (c1 <= 200000)
Planning Time: 0.065 ms
Execution Time: 48.800 ms
(7 rows)
demo=# set work_mem to '64kB';
SET
demo=# explain (analyze on, costs off, timing off)
demo-# select * from t where c1 <= 200000;
QUERY PLAN
------------------------------------------------------------------
Bitmap Heap Scan on t (actual rows=200000 loops=1)
Recheck Cond: (c1 <= 200000)
Rows Removed by Index Recheck: 687823
Heap Blocks: exact=752 lossy=4654
-> Bitmap Index Scan on t_c1_idx (actual rows=200000 loops=1)
Index Cond: (c1 <= 200000)
Planning Time: 0.138 ms
Execution Time: 85.208 ms
(8 rows)
4.11 错误的执行计划图¶
这是最难以发现的问题,只有通过经验才能发现。
我们在前面看到,work_mem 不足会导致哈希使用多个批次。
但如果 Postgres 认为不使用散列连接而使用嵌套循环更节省开销呢?现在没有什么 "突出 "的情况,就像我们在本节其他部分看到的那样,但增加 work_mem 会让执行计划更倾向于哈希连接。
了解你的查询何时应该有特定的执行计划轮廓,并注意到它何时有不同的计划轮廓,可以为 PostgreSQL 提供一些非常好的优化机会。
4.12 分区表维护¶
分区有两个目的:维护maintenance和并行化parallelization(分片查询)。
当表变得非常大时,默认auto vacuum设置允许的死元组数量也会增加。
对于一个只有 10 亿行的表来说,要等到 200,000,000 行被更新或删除后才会开始清理。
- 所以对于为分区的大表,要定时手动进行vacuum
在大多数工作负载中,这需要一段时间才能实现。
当出现这种情况时,或者更糟的是,当缠绕出现时,就到了支付清理开销的时候了,单个auto vacuum worker 必须扫描整个表,收集死行列表。每个死行列表占用 6 个字节,因此大约需要 1.2GB 内存来存储。
然后,它必须逐次扫描表中的每个索引,并删除列表中的条目。最后,再次扫描表,删除死行
如果你没有或无法容纳 1.2GB 的 autovacuum_work_mem,那么整个过程就会分批重复。
如果在操作过程中,某个查询需要的锁与 autovacuum 发生冲突,后者就会礼貌地退出,并从头开始。
不过,如果 autovacuum 要防止缠绕,查询就必须等待。
autovacuum 使用可见性映射来跳过表中自上次vacuum后未被触及的大片区域,9.6 版本在anti-wraparound vacuums方面更进一步,但索引方法不存在这样的优化,它们每次都要被完全扫描。
更重要的是,表中留下的空洞可以通过未来的插入/更新来填补,但索引中的空洞却很难再利用,因为索引中的值是有序的。
- 所以定期重建索引是非常有必要的,索引的冗余是不会被再利用的
更少的vacuum意味着索引需要更频繁地重建索引才能保持性能。在 PostgreSQL 11 之前,这需要锁定表以防止写入,但 PostgreSQL 12 可以并发地重建索引(create index concurrentlly )。
有时可以使用分区来消除vacuum的需要.如果表中保存的是时间序列数据,基本上可以 插入并遗忘,那么上述问题就小得多。
一旦旧行被冻结,autovacuum 就不会再查看它们(如前所述,自 9.6 版起)。这里的问题在于保留策略。如果数据只保留 10 年,然后可能在冷存储中归档后删除,这就会产生一个新数据最终会填补的漏洞,表就会变得支离破碎。这将导致任何 BRIN 索引完全无用。
常见的解决方案是按月(或所需的任何粒度)分区,然后程序变为:分离旧分区,转储存档,删除表。现在,根本就没有什么要vacuum的了。
至于并行化,如果有随机访问的大表,如多租户设置,最好按租户进行分区,以便将每个租户(或租户组)放在单独的表空间上,从而改善 I/O。
对于分区来说,一个通常失效的原因是错误地认为多个小表比一个大表更有利于提高查询性能。这往往会降低性能。
这些说明应能为大多数 OLTP 工作负载提供一个良好的起点。监控和调整这些设置和其他设置对于为特定工作负载获得 PostgreSQL 的最高性能至关重要。我们将在今后的文档中介绍监控和优秀 DBA 的其他日常任务。
⚠️补充vacuum详细流程介绍
5. 总结¶
这些建议应该为大多数OLTP工作负载提供一个良好的起点。
监控和调整这些以及其他设置对于在您特定的工作负载中获得PostgreSQL最佳性能至关重要。
我们将在未来的文档中介绍监控和其他日常任务,这是一个优秀数据库管理员的必备技能。